Rui Vasconcelos
on 23 April 2021
What is KFServing?
TL;DR: KFServing is a novel cloud-native multi-framework model serving tool for serverless inference.
A bit of history
KFServing was born as part of the Kubeflow project, a joint effort between AI/ML industry leaders to standardize machine learning operations on top of Kubernetes. It aims at solving the difficulties of model deployment to production through the “model as data” approach, i.e. providing an API for inference requests.
What is KFServing?
KFServing abstracts away the complexity of server configuration, networking, health checking, autoscaling of heterogeneous hardware (CPU, GPU, TPU), scaling from zero, and progressive (aka. canary) rollouts. It provides a complete story for production ML serving that includes prediction, pre-processing, post-processing and explainability, in a way that is compatible with various frameworks – Tensorflow, PyTorch, XGBoost, ScikitLearn, and ONNX.
Check out the KFServing repository on github for a deeper dive.
How does it work?
KFServing uses two well-known cloud-native technologies at its core: Knative and Istio.

Knative is a Kubernetes-based platform to deploy and manage modern serverless workloads. This grants to KFServing the properties of:
- Scaling to and from zero: optimizing costs associated with inference
- Auto-scale of GPUs and TPUs: reducing latency with specialized hardware at a cost per demand
Istio is a service mesh technology that works through the concept of Kubernetes sidecars. A sidecar container is added to every pod, handling all network traffic. This enables:
- Canary roll-outs: allowing for safe model updates across users
- Traffic to the model: routing and ingress management
- Observability: tracing, monitoring, and logging features for your models
- Load balancing: HTTP, gRPC, WebSocket, and TCP traffic
- Security: authentication, authorization, and encryption of service communication at scale
KFServing itself provides a Kubernetes Custom Resource Definition – an object that extends the Kubernetes API – specific for serving machine learning models saved on various frameworks, such as Tensorflow, PyTorch, XGBoost, ScikitLearn, and ONNX, into production environments.
How can I use it?
To use KFServing, you need to create a YAML file of the “InferenceService” common interface. You can see an example below:
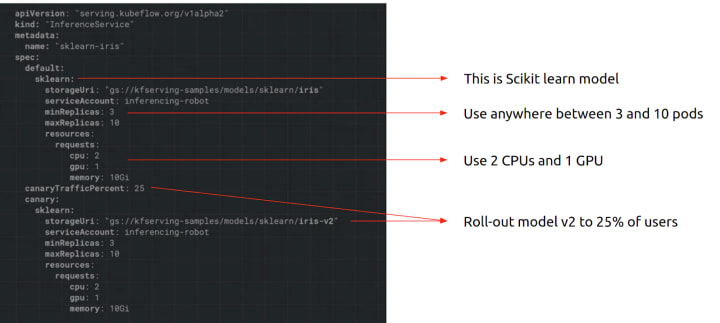
As you can see, it is possible to specify things like what hardware should be used and to what extent it should scale up or down, and what framework is the model saved in.
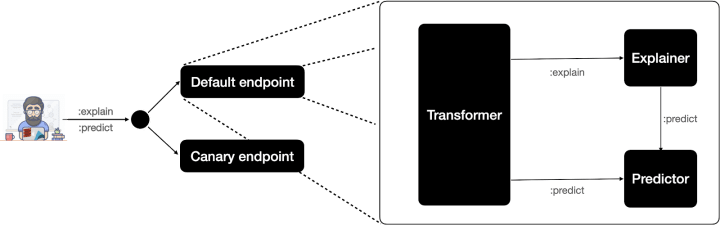
Progressive / Canary rollouts
Upon defining a canary in the InferenceService YAML, a canary end-point will be created and traffic will be routed using Istio to comply with your required quotas. This is combined with the transformer, explainer and predictor according to the following architecture:
Pre-processing and post-processing data for inference
KFServing includes the concept of “Transformers”, allowing you to orchestrate transformations to the data before or after inference.
One use case to this is, e.g. your model is good at classifying images of 28×28 pixels, however, your new data may come from a high-resolution camera. To comply with your model requirements, you have to pre-process this data through a transformation to the new data and only then run inference.
You can accomplish this by defining a docker image with your pre-processing or post-processing steps and adding it to the InferenceService YAML that defines your model serving job.

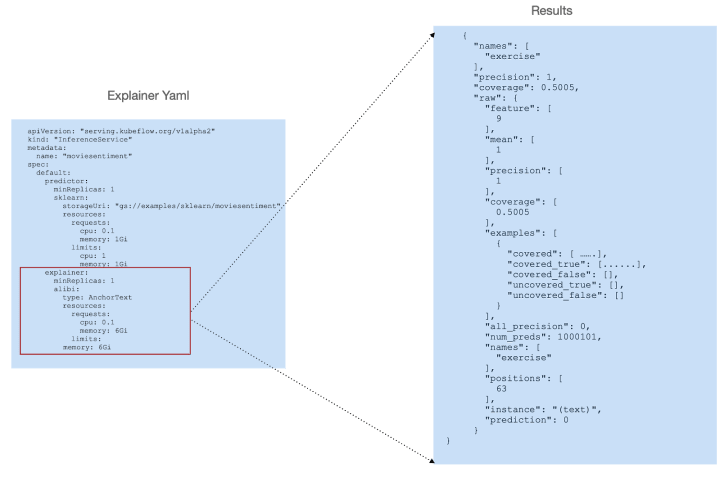
Model explainability
One optional feature of KFServing, that makes use of Seldon Alibi, is the ability to add an “explainer” that enables an alternate data plane, providing model explanations in addition to predictions.
Learn more about KFServing and Kubeflow
Canonical provides Kubeflow training for enterprises alongside professional services such as security and support, custom deployments, consulting, and fully managed Kubeflow – read more on Ubuntu’s AI services page.
Try it out now!
If you’re looking for standalone KFServing, deploy the KFServing operator for a low ops deployment.
If you’re looking for a full-fledged MLOps platform. Get the latest Kubeflow packaged in Operators, providing composability, day-0 and day-2 operations for all Kubeflow applications including KFServing.